新注册的未经验证的账户面临着更严格限制,每天最多发300条推文。随后,马斯克又发布一条推文称,很快,已验证的账户浏览推文数量的限制将增加到8000条,未验证的账户将增加到800条,新注册的未验证用户将增加到400条。马斯克此前曾对推特上的数据抓取表示担忧,并暗示他可能会对不良行为者采取行动。
今年4月,他对微软“非法”使用推特数据表示愤怒,显然是指微软与人工智能公司OpenAI的合作,OpenAI在“来自互联网的大量不同文本数据集”上训练人工智能模型,马斯克说,“他们非法训练使用推特数据。诉讼时间到了。”本周早些时候,推特开始限制未登录帐户的人通过桌面和移动设备上的网络浏览器访问推文和个人资料。

根据马斯克的说法,这个限制措施是临时的,随时可能改动或取消。至于原因,他提到是因为“数百个组织(也许更多)正在非常频繁地抓取Twitter数据”,使得服务器受到了巨大的负担,不得不经常在紧急情况下上线大量服务器以保证平台正常运行。他指的其实是一些人工智能公司为了训练大型语言模型的在推特上抓取大量推文(对话)作为训练数据。
因为LLM需要从大量真实的人类对话中学习。但训练数据的质量对于AI模型的表现非常重要。像Twitter和Rdt美版贴吧(这个网站全名打出来貌似会被屏蔽)这样的社交平台上,有数十亿的帖子,对话质量都很高,被认为是优质UGC(用户生成内容),因此常被人工智能公司用来训练AI模型。像OpenAI、谷歌等公司的大模型早已将这些平台的公开数据用于自家AI语言模型的训练之中。
但是这些平台也希望用户能为这些数据付费,谁也不想看着自己平台上生产的优质内容被别的公司白白拿去使用,同时还要承受着频繁的API访问带来的服务器维护压力和额外成本,颇有一番给别人做嫁衣的意味。所以,一边是平台想着收钱,另一边是用户想着白嫖,矛盾就这样产生了。上个月美版贴吧就因为其公司CEO决定要提高API接口的使用费用而遭到大量版主的抵制,还发起了“灭灯”运动——关闭板块访问,超过8000个板块被设置为“私人板块”,外人无法访问,但是最后,平台也没有妥协。
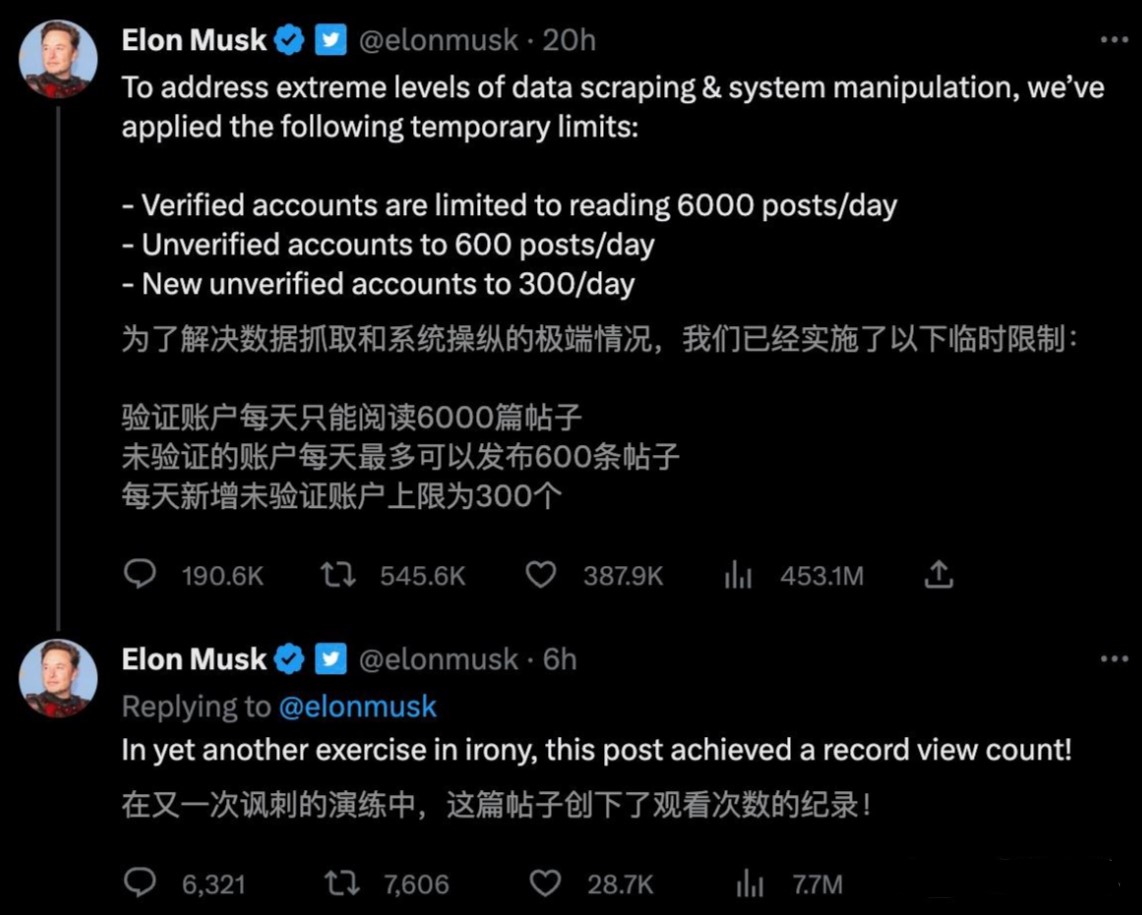
推特此前也调整过API的收费策略。此次又整出来一个限制每日浏览量,基本上也证实了这些平台的态度——想白嫖数据,难了。限制浏览量这个国内基本不会搞,爬虫的基本上是反作弊或安全团队的事情,比如通过 IP、抓取特征、加验证码、加限制提醒,普通用户不会看到限额,因为对于普通用户,更多的浏览量其实是有更多而 ADLoad 、更多的活跃时长、更多的在线用户和其他销售机会,对产品是正向的数据。
Twitter 为了对付爬虫,把普通用户也直接当做爬虫对待了。其实 Twitter 可以直接加上宽泛的限制,碰到问题自己调调参数就行了,现在直接粗暴的来一个方案,很埃隆马斯克风格,简单粗暴,碰到啥想到方法就干,只要有效就好。国内的企业至少从用户体验角度习惯让用户看到简单,哪怕底层实现的更复杂。
推特有很多更好的办法可以解决这个问题,正常的反爬是不应该牺牲用户体验的。如果不想被爬数据,可以识别高频访问的 IP、账号,有针对性的去做 block 或者 limit,而不是去限制所有用户的使用,去同时恶心用户和对手。更何况,限制账号的浏览频率,也只是增加了对方的成本而已,如果爬数据的人真觉得推特的数据价值很高,也可以用更多的账号,更慢的频率去进行抓取。
点击收藏本站,随时了解时事热点、娱乐咨询、游戏攻略等更多精彩文章。




































